Configurar vLLM + WSL2
Descubre cómo configurar vLLM junto a WSL2
Tabla de contenidos
- 1 - Qué es vLLM
- 2 - Configurar WSL
- 3 - Configurar vLLM para inferencia por GPU
- 4 - Conclusión
- 5 - Referencias
En este post te presento como ejecutar cualquier LLM de manera local en Windows.
Qué es vLLM
vLLM es una librería optimizada para la realizar inferencia a grandes modelos de lenguaje (LLMs) y servirlos de manera sencilla a través de su motor de API incorporado, además la API está pensada para ser compatible con los modelos de OpenAI.
Configurar WSL
En este ejemplo utilizaremos WSL (Windows Subsystem for Linux). En el caso de que no lo tengas instalado, necesitarás escribir en la barra de búsqueda “Habilitar características de windows”, para lo cual se te abrirá un cuadro y donde necesitarás habilitar la opción “Windows Subsystem for Linux” como se muestra en la imagen adjunta:
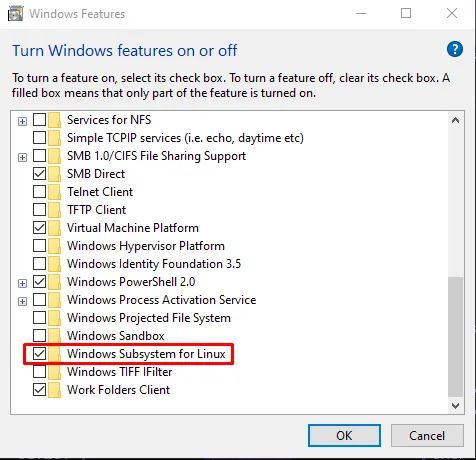
Una vez hayas chequeado esta opción es necesario reiniciar el equipo para que se apliquen los cambios. Posteriormente, deberás abrir powershell y ejecutar los siguientes comandos:
wsl --set-default-version 2
wsl --install -d ubuntu
wsl --set-default ubuntuEsto permitirá que se configure WSL a la versión 2 y se instale Ubuntu 24.
Configurar vLLM para inferencia por GPU
Una vez dentro de WSL y antes de configurar vLLM, es necesario tener instalados los siguientes paquetes esenciales:
sudo apt update
sudo apt install -y python3-venv
sudo apt install -y build-essential
sudo apt install python3.12-devAhora crearemos un entorno virtual para Python y lo realizamos a través de los comandos:
python3 -m venv myenv
source myenv/bin/activateUna vez dentro del entorno virtual, es necesario instalar los siguientes paquetes que son requisitos para ejecutar vLLM:
(myenv) pip install torch torchvision
(myenv) pip install vllm
(myenv) pip install transformers accelerate safetensors
(myenv) pip install torch-c-dlpack-extDebemos descargar un repositorio del LLM a ejecutar desde Hugging Face, después le creamos una carpeta (en este caso es liquidai_lfm2_2.6b), nos movemos a la carpeta del modelo y ejecutamos los siguientes comandos:
(myenv) cd /mnt/e/Github/myllm/model/liquidai_lfm2_2.6b
(myenv) vllm serve . --dtype float16 --max-model-len 2048 --gpu-memory-utilization 0.8 --enforce-eagerAhora se inicializará vLLM, el cual una vez cargue el motor de API estará escuchando a través de la URL:
Conclusión
En este post hemos visto como configurar vLLM dentro de WSL, lo cual nos permite ejecutar distribución de Linux que expone una API con la que podemos interactuar con un LLM desplegado localmente.
Si te ha gustado este post no dudes en compartirlo con alguien que le pueda interesar ¡Gracias por leer!