Ejecuta tu primer LLM local junto a ChateAI
Descubre como configurar un LLM para que corra localmente en tu equipo

Tabla de contenidos
- 1 - ¿Cómo habla un LLM?
- 2 - ¿Qué es ChateAI?
- 3 - Configurar un LLM para ejecución local
- 4 - Ejecutar ChateAI desde la fuente
- 4.1 - Frontend
- 4.2 - Backend
- 4.3 - Compilar binarios
- 5 - Conclusión
- 6 - Referencias
En este post presento cómo ejecutar localmente un LLM e integrarlo con ChateAI. Puedes visualizar el repositorio desde este enlace.
¿Cómo habla un LLM?
Cuando interactuamos con gran modelo de lenguaje (LLM) en producción, la comunicación con el modelo funciona enviado un mensaje estructurado en JSON. Un ejemplo sencillo sería el siguiente:
{
"messages": [
{
"role": "user",
"content": "Hola, ¿cómo estás? Describe algo en 3 líneas."
}
]
}Este esquema se basa en un juego de roles, donde el cliente llamado “user” envía un mensaje y el modelo llamado “assistant” responde, La respuesta típica del LLM sigue la especificación de OpenAI e incluye tanto el contenido generado como metadatos adicionales:
{
"id": "chatcmpl-977429d83218ac8c",
"object": "chat.completion",
"created": 1769099689,
"model": ".",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "¡Hola! Estoy bien, gracias por preguntar. Imagina un atardecer en la playa: el cielo se tiñe de naranja y púrpura mientras las olas suaves rompen en la orilla, creando un sonido relajante que acaricia el alma. Es un momento de paz y belleza natural que invita a la reflexión.",
"refusal": null,
"annotations": null,
"audio": null,
"function_call": null,
"tool_calls": [],
"reasoning": null,
"reasoning_content": null
},
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null,
"token_ids": null
}
],
"service_tier": null,
"system_fingerprint": null,
"usage": {
"prompt_tokens": 25,
"total_tokens": 109,
"completion_tokens": 84,
"prompt_tokens_details": null
},
"prompt_logprobs": null,
"prompt_token_ids": null,
"kv_transfer_params": null
}El desafío surge cuando deseamos conversaciones largas, ya que las respuestas que entrega el modelo son largas y almacenar todo el historial puede volverse complejo rápidamente.
¿Qué es ChateAI?
Para resolver el problema anterior desarrollé ChateAI, la cual es una herramienta que facilita la interacción con LLMs locales, además cuenta con las siguientes características:
- Almacenamiento local: Tus conversaciones se almanacenarán en una base de datos local, permitiendo que siempre puedas conservar la privacidad de tus conversaciones.
- Búsqueda de chats: Puedes utilizar la función de búsqueda para encontrar la información que buscas en el historial de conversaciones.
- Soporte para markdown: Formateo automático de respuestas generadas en Markdown por el LLM.
- Finetuning de modelos: Funciones personalizadas para añadir de forma sencillos los parametros de tuneo que permiten que el LLM entregue mejores respuestas.
- Multiplataforma: Al estar diseñado como una aplicación multiplataforma permite que cualquiera pueda descargarlo y ejecutarlo en su equipo.
Configurar un LLM para ejecución local
Utilizaremos Hugging Face para buscar el modelo que deseamos implementar. Existen modelos, como la familia LLaMa de Meta, que son Gated model, lo cual significa que para poder descargar los archivos del modelo debemos iniciar sesión dentro de Hugging Face y pedir acceso al mismo para poder acceder al repositorio.
En este ejemplo, utilizaremos el modelo LFM2-2.6B de Liquid AI, el cual tiene unos requisitos no tan elevados de GPU para correr en local. Nos dirigimos al siguiente enlace, clickeamos la pestaña “Files and versions” y seleccionamos la opción “Clone repository”
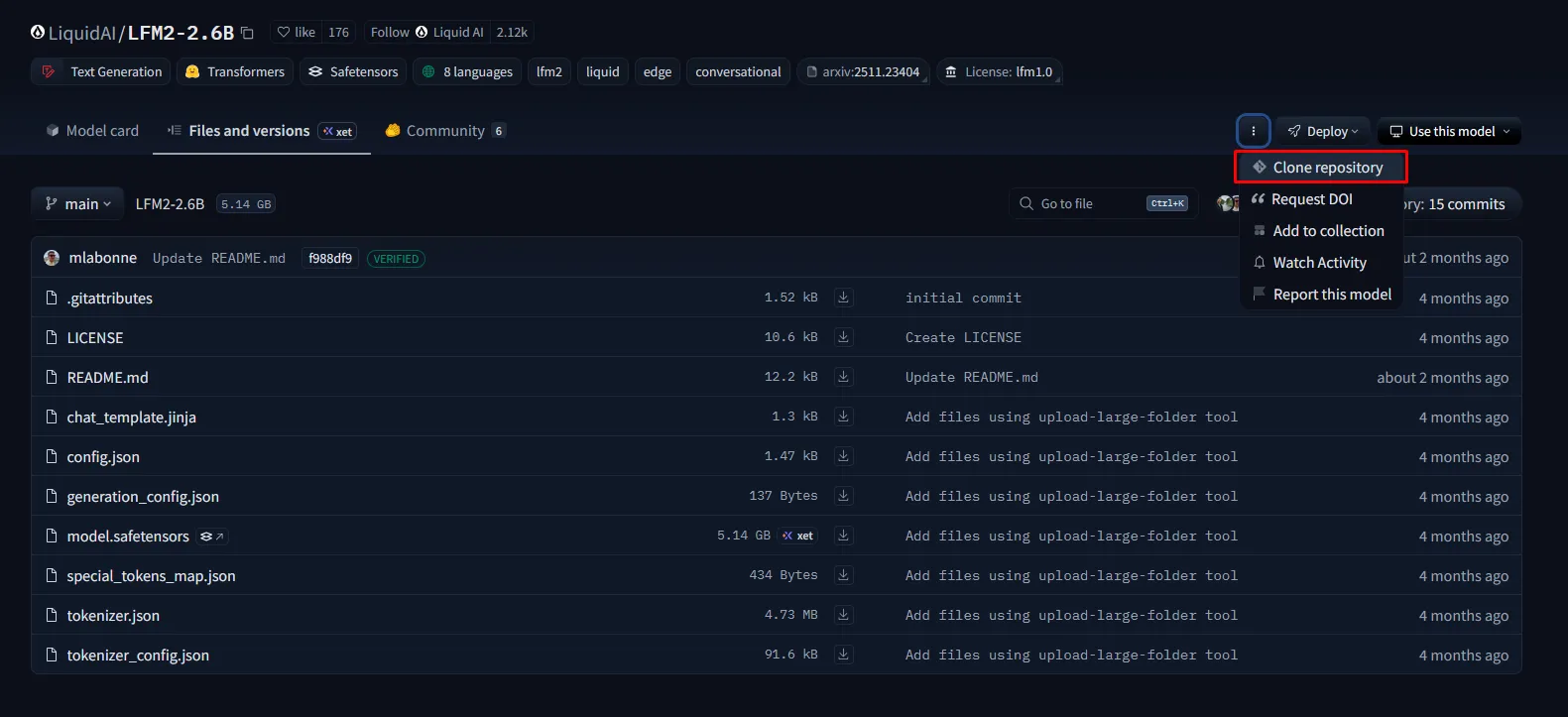
Nos aparecerán varias opciones para descargar el repositorio, pero la más sencilla es ejecutar el comando:
git clone https://huggingface.co/LiquidAI/LFM2-2.6BUna vez descargado el repositorio, deberemos tener instalado en nuestro equipo Docker Desktop, este nos permitirá desplegar el servidor LLM en producción de forma local.
Ejecutar ChateAI desde la fuente
ChateAI utiliza el framework Wails, el cual permite convertir una aplicación web en una aplicación de escritorio nativa. Para ello se utiliza como backend el lenguaje de programación Go, permitiendo ejecutar código desde el lado del servidor, y para el frontend se utiliza el empaquetador Vite, lo cual permite que se pueda integrar con varios frameworks de javascript y en particular para este proyecto se utiliza Solid.js.
Frontend
Para correr el frontend son necesarias las siguientes dependencias:
- Node.js: Es un motor escrito en Javascript, el cual trabajará por detrás como el renderizador de Vite, se puede descargar a través de este enlace.
- PNPM: Cuando instalamos Node.js, el gestor de paquetes por defecto es npm, aunque suelo utilizar PNPM ya que es más rapido y seguro para la gestión de paquetes, recomiendo instalar utilizando corepack como se describe en este enlace.
Una vez instaladas estas herramientas, nos dirigiremos a la carpeta chateai/frontend y ejecutaremos el comando:
pnpm installEl cual instalará todas las dependencias necesarias para correr el frontend.
Backend
Para correr el backend se necesitan las siguientes dependencias:
- Go: Es el lenguaje de programación en el cual fue escrito el backend de Wails, se puede descargar desde este enlace
- Wails: Por último necesitamos tener instalado Wails para poder ejecutar nuestra aplicación, acá se describe como instalarlo
Para comprobar que Wails esté funcionando correctamente ejecutaremos desde el comando:
wails doctorEste comando ejecutará un chequeo para ver si están todas las dependencias instaladas para que Wails pueda compilar los binarios.
Compilar binarios
Dependiendo de la arquitectura a la que deseemos compilar existirán algunas diferencias entre los comandos a ejecutar, pero acá se describen las opciones más comunes:
- Windows: Se debe tener instalado Wails en un computador con Windows y se ejecuta el comando:
wails build --platform windows/amd64 -o chateai_win_amd64.exe- Linux: Se debe tener instalado Wails en un computador basado en una distribución de Linux y se ejecuta el comando:
wails build --platform linux/amd64 -o chateai_linux_amd64 -tags webkit2_41- MacOS: Se debe tener instalado Wails en un computador con MacOS y se ejecuta el comando:
wails build --platform darwin/universal -o chateai_mac.appNOTA: Wails no permite realizar cross-compilation, por tanto para ejecutar las versiones de Windows y Linux se puede hacer en la misma máquina con WSL habilitado. Pero en el caso de MacOS se necesita un equipo físico para compilarlo.
Conclusión
En este post vimos cómo configurar un LLM para su uso local y cómo ChateAI facilita tu experiencia al darte una interfaz gráfica sencilla para comunicarte con el modelo.
Si te ha gustado este post no dudes en compartirlo con alguien que le pueda interesar ¡Gracias por leer!